
多表联合查询
· 我们知道,查询的时候的同一个条件不能重叠,比如下面这一句就是错的,C#的查询条件出现了两次。
SELECT DISTINCT `S#` FROM `SC` WHERE `C#`="001" AND `C#`="002";· 但是我们难免会遇到必须要使用复合条件的情况,这样我们就自然而然的想到之前学过的表连接了。
· 在SQL中,表连接的语法如下:
SELECT `列名` [, `列名2`,...]
FROM `表名1`, `表名2`, ...
WHERE 检索条件;等值连接
· 等值连接是比较常用的连接方式,我们用一个例子来理解一下。
· 有以下三张表,需要查询每个学生及其选修课的情况:
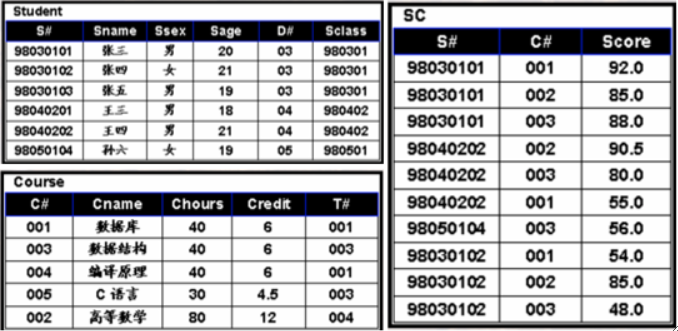
SELECT `Student`.*, `SC`.*
FROM `Student`, `SC`
WHERE `Student`.`S#` = `SC`.`S#`;· 需要注意,因为Student和SC表里面都有S#这一列,因此要带上表名来表示是哪个表里的S#。
· 其实,第二行就相当于进行笛卡尔积,第三行就是对笛卡尔积的结果进行筛选,因此必须要有连接条件。
· 上面的查询的结果是这样的:
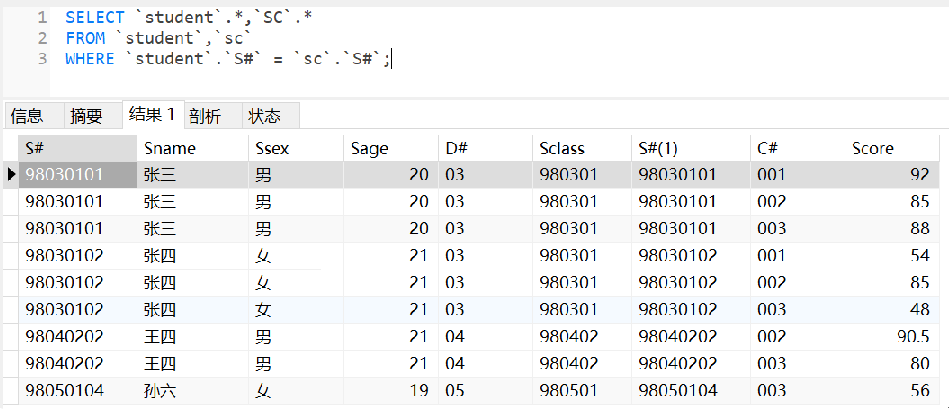
· 可以看到出现了两列S#,如果我只想保留一列,那就在查询结果上改一改即可:
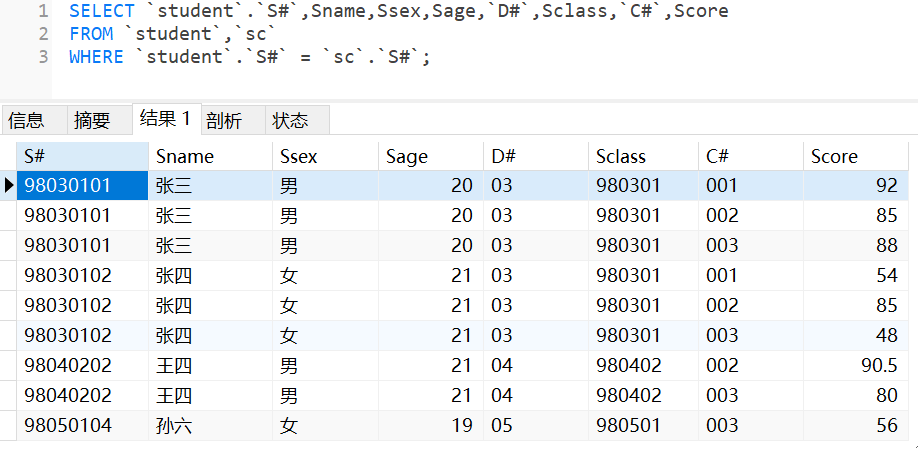
· 如果不写查询条件的话,就会直接出笛卡尔积:
SELECT *
FROM `Student`, `SC`;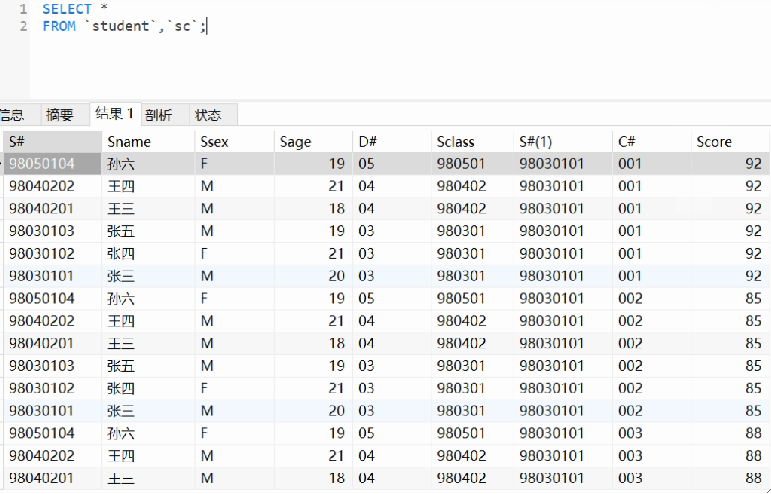
· 当我们需要自己和自己连接的时候,就涉及到一个改名操作了。
· 我们拿一开始的问题做例子,在下面的表中筛选出即学过001也学过002课程的学生。
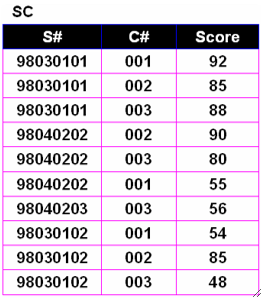
SELECT `SC`.`C#`
FROM `SC`, `SC` AS `SC1` # 改名,避免歧义
WHERE `SC`.`S#` = `SC1`.`S#`
AND `SC`.`C#`="001"
AND `SC1`.`C#`="002";· 等值连接还能写成更容易阅读的形式:
SELECT `SC`.`C#`
FROM `SC`
INNER JOIN `SC` AS `SC1` # 这种写法能让人一看就懂
ON `SC`.`S#` = `SC1`.`S#`
WHERE `SC`.`C#`="001" AND `SC1`.`C#`="002";· 我们来看一个例子,有一张Employee表,请找出工资比自己的经理多的人:
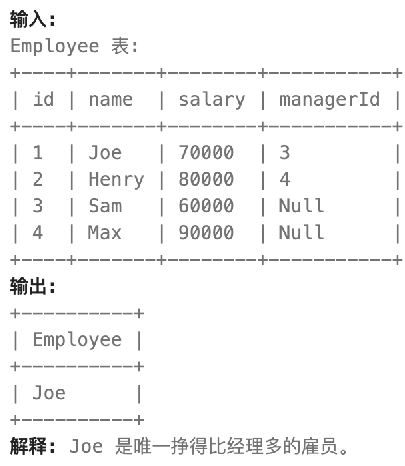
SELECT `name` as `Employee` # 这个改名是因为输出规定
FROM Employee
INNER JOIN Employee as `e` # 这个改名是为了避免歧义
ON Employee.`id` = e.`manaerId`
WHERE Employee.`salary` > e.`salary`;· 除了等值连接之外,还支持左外连接和右外连接,但是不支持全外连接(后面用其他方法实现)。
· 我们来看一个例子,有一张Employee表和Bonus表,请找出奖金小于1000元的人:
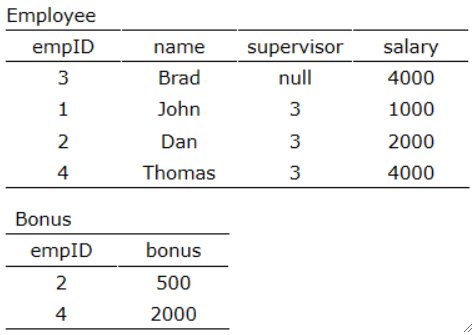
SELECT `name`, `bonus`
FROM `Employee`
LEFT JOIN `Bonus`
ON `Employee`.`empID` = `Bonus`.`empID`
WHERE `bonus` IS NULL OR `bonus` < 1000; # 没奖金也算!· 注意我们要使用左连接,因为要保留所有的人!
· 最后看一个例子:
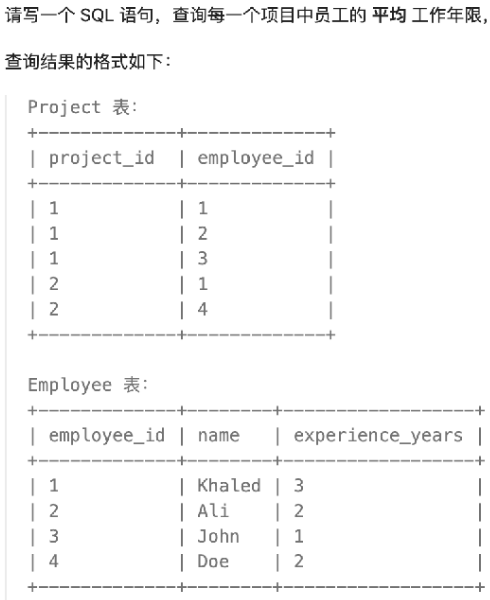
SELECT `Peoject`.`project_id` AVG(`experience_years`) AS `average_years`
FROM `Project`
INNER JOIN `Employee`
ON `Project`.`employee_id` = `Employee`.`employee_id`
GROUP BY `Project`.`project_id`;嵌套查询
· 首先,我们把一个查询语句称为一个查询块:
SELECT 列名1 [[, 列名2]...]
FROM 表名
[WHERE 检索条件];· 如果把一个查询块放到WHERE子句或HAVING子句里面,这样的查询就被称为嵌套查询:
SELECT `Sname` # 外层查询,父查询
FROM `Student`
WHERE `S#` IN (
SELECT `S#` # 内层查询,子查询
FROM `SC`
WHERE `C#` = "002"
);· 注意,子查询要使用括号括起来;两个查询要用IN来连接,子查询的结果要和父查询的筛选条件的目标在同一个域中。
· 举个例子,有一张Student表,现在要找出和李勇在同一个系的同学:
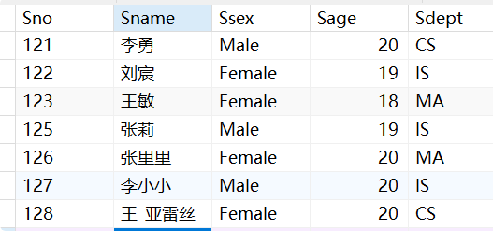
SELECT *
FROM `Student`
WHERE `Sdept` IN (
SELECT `Sdept`
FROM `Student`
WHERE `Sname` = "李勇"
);· 再看一个例子,在下面三张表中查询选修了“数据库”的学生的学号姓名:
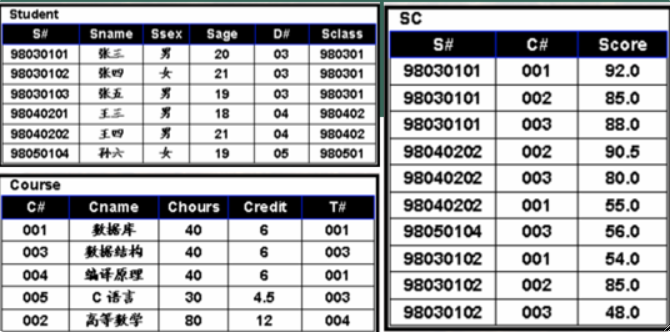
SELECT `Student`.`S#`, `Student`.`Sname`
FROM `Student`
WHERE `S#` IN (
SELECT `SC`.`S#`
FROM `SC`
WHERE `SC`.`C#` IN (
SELECT `Course`.`C#`
FROM `Course`
WHERE `Cname` = "数据库"
)
);· 注意,当子查询返回的值确定是一个的时候,IN可以更换为等号(=),如刚刚到例子可以改为:
SELECT *
FROM `Student`
WHERE `Sdept` = ( # 这里的IN改为等号
SELECT `Sdept`
FROM `Student`
WHERE `Sname` = "李勇"
);· 当然,嵌套查询也可以使用比较运算符,但是要注意子查询必须要返回单值,且对象在同一个域中!
· 也可以使用ANY,ALL谓词来修饰子查询,ANY指的是子查询结果中的任意一个值,ALL指的是子查询结果中的所有值。
· 举个例子,在Student表中查询非IS系中比IS中任意一个学生年龄小的学生姓名和年龄:
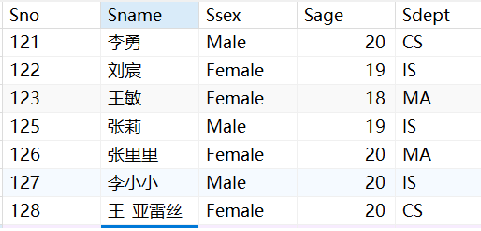
SELECT `Sname`, `Sage`
FROM `Student`
WHERE `Sage` < ANY(
SELECT `Sage`
FROM `Student`
WEHRE `Sdept` = "IS"
)
AND `Sdept` != "IS";· 在看一个例子,找出年龄最小的学生的姓名和年龄:
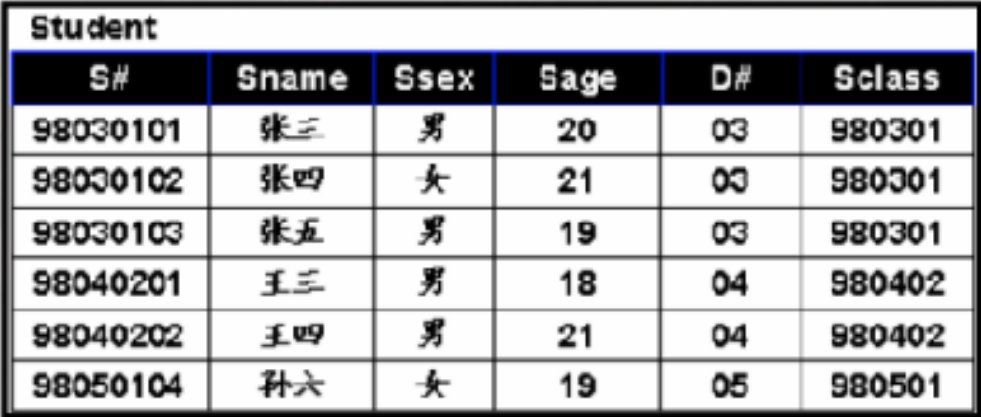
SELECT `Sname`, `Sage`
FROM `Student`
WHERE `Sage` <= ALL( # 注意是用小于等于,不然就筛不出任何一个结果了
SELECT `Sage`
FROM `Student`
);
# 当然还有另一种写法
SELECT `Sname`, `Sage`
FROM `Student`
WHERE `Sage` <= (
SELECT MIN(`Sage`)
FROM `Student`
);基于派生表的查询
· 我们知道了嵌套查询可以在WHERE或HAVING中嵌套,但其实还可以在FROM中嵌套。
· 用户自己创建的表叫做基本表,SELECT的结果叫做派生表。
· 有时候我们可能有这个想法,先把一个表筛选出来作为中间变量,再把它用到一个其他查询中,这个时候派生表就派上用场了。
· 举个例子,在SC表中找出每个学生自己最高分的课程号:
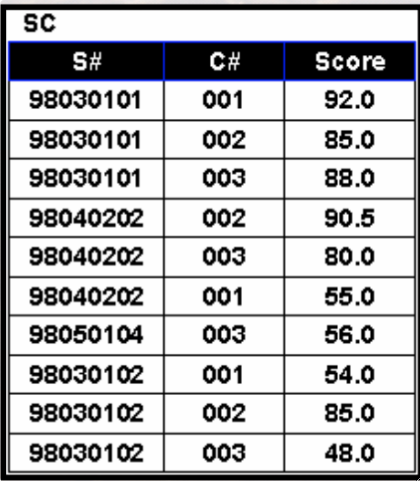
SELECT `S#`, `C#`
FROM SC, (
SELECT `S#`, MAX(`Score`)
FROM `SC`
GROUP BY `S#`
) AS `m`(`m_S#`, `m_score`) # 给派生表取个别名m,里面的两列分别取别名m_S#和m_score
WHERE `S#` = `m`.`m_S#`
AND `Score` = `m`.`m_score`;· 我们来分析一下这个查询。
· 首先子查询,查询到了每个学生自己的最高分是多少分;然后给查询出来的表取一个别名;然后再通过等值连接连接原表和派生表,通过分数确定最高分的课程。
集合查询
· 当然,我们也可以对查询结果进行求交集、并集和做差。
· 我们使用UNION来把两个查询结果进行合并,系统会自动去掉重复元组;使用UNION ALL可以保留重复元组。
· 看个简单的例子,筛选出下表中既选修了001也选修了002课程的同学:
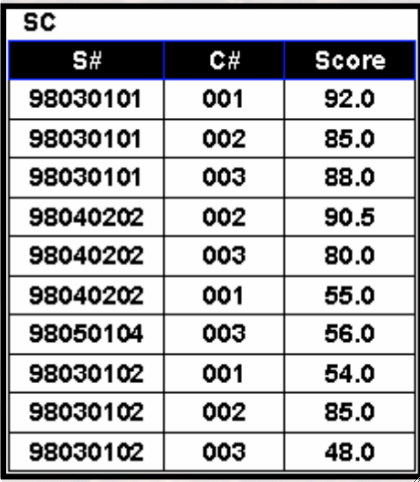
SELECT `S#`
FROM `SC`
WHERE `C#` = "001"
UNION
SELECT `S#`
FROM `SC`
WHERE `C#` = "002";· 同时,我们也可以使用UNION来实现全外连接:
SELECT *
FROM `Student`
LEFT JOIN `SC` # 先左外连接
ON `Student`.`S#` = `SC`.`S#`
UNION
SELECT *
FROM `Student`
RIGHT JOIN `SC` # 再右外连接
ON `Student`.`S#` = `SC`.`S#`;· 我们使用INTERSECT将多个查询结果取交集,系统会自动去掉重复元组;使用INTERSECT ALL会保留重复元组。
· 继续上面那张表,这次要选出学了001又学了002课程的学生:
SELECT `S#`
FROM `SC`
WHERE `C#` = "001"
INTERSECT
SELECT `S#`
FROM `SC`
WHERE `C#` = "002";· 真是太优雅了。
· 我们使用EXCEPT来对查询结果求差,我们通过一个例子来理解。
· 还是刚刚的表,如果我要选出不选002课程的同学,一个很直观的想法是:
SELECT `S#`
FROM `SC`
WHERE `C#` != "002";· 但其实这样子会把98040202这个人也筛出来了,因为他选了002和003,即使002被筛出去了,003也被留下来了。
· 这个时候,我们就可以使用求差来避免这个问题:
SELECT DISTINCT `S#` # 先把所有人筛出来,去重
FROM `SC`
EXCEPT # 然后去掉
SELECT `S#` # 选过002课程的人
FROM `SC`
WHERE `C#` = "002";