插入数据
· 我们使用INSERT语句来向数据库中添加新的数据:
INSERT INTO `表名` VALUES(常量1,常量2,...);· 注意,插入的每一个值都要和字段顺序一一对应,并且每个值都要属于其字段所属的域。
· 假设有下面这张student表:
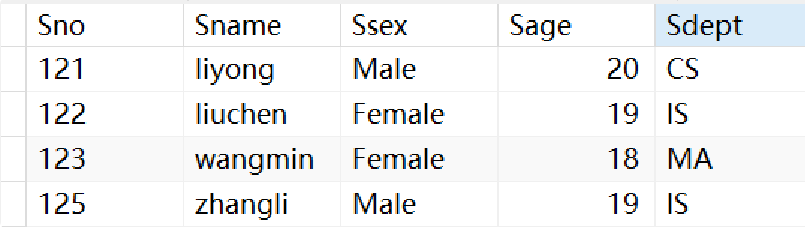
· 执行下面的语句会报错,因为Sno的域是varchar,输入int型不满足域的要求:
INSERT INTO `student` VALUES(126, "huangqirui", "Male", 21, "MA");· 执行下面的语句会报错,因为输入了一个已经存在的元组,不满足关系中元组唯一性:
INSERT INTO `student` VALUES("121", "liyong", "Male", 20, "MA");· 执行下面的语句会报错,因为字段的数量不相同,缺了一个:
INSERT INTO `student` VALUES("126", "huangqirui", "Male", 21);· 当然,如果表设置了默认值,那可以用下面这种写法来指定填入的数据,其他没填的数据会自动使用默认值填充:
INSERT INTO `student`(`Sno`, `Ssex`, `Sname`) VALUES("126", "Male", "huangqirui");单表查询
简单查询
· 查询有很多种,我们先从最简单的单表查询入手。所谓单表查询,顾名思义,就是只在一张表内进行查询。
· 我们来看看最基础的查询语句长什么样:
SELECT 列名1 [[列名2], [列名3], ...] FROM 表名 [WHERE 检索条件];· 看上去有点抽象,我们一个个看。
· 首先,查询的关键字是SELECT;然后后面要跟上你想看到的列的数据,你想看到哪些列就跟上哪些列的列名;然后FROM后跟上要从哪张表里面查;然后WHERE是筛选条件,后面会讲。
· 每个英文单词后面跟着的叫做子句,如SELECT子句,FROM子句,WHERE子句。
· 注意,查询的关键字顺序很严格,请严格按照上面的顺序来书写。
· 这个语句的作用其实就是从表中依次取出一个个元组,然后检查是否满足检索条件,如果满足则将元组(或分量组)放入结果表。
· 我们来看一些例子,首先我们有一张student表:
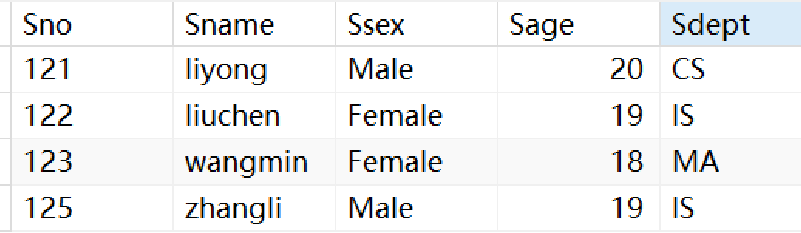
· 下面的语句会把整张表筛选出来,*代表的就是所有列:
SELECT * FROM student;· 下面的语句用于查询所有学生的学号和姓名,类似于\pi_{Sno,Sname}(Student):
SELECT `Sno`,`Sname` FROM student;· 下面的语句会筛选出性别这一列:
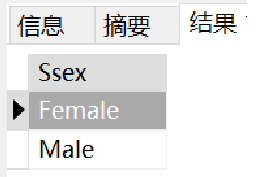
SELECT `Ssex` FROM student;但是结果是这样的:
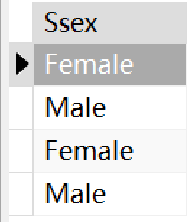
· 这看上去有点奇怪,因为我们只想知道有多少性别有多少类,不需要重复的查看性别,因此我们可以用DISTINCT来实现去重:
SELECT DISTINCT `Ssex` FROM student;这看上去就合理多了:
· 接下来我们玩点花的。
· 首先,我们可以对查询后的值做运算,当然,只有数值型才能做运算:
SELECT 2023-`Sage` FROM student;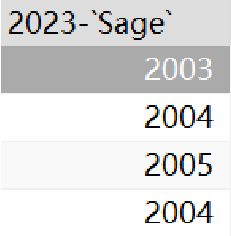
· 然后我们可以使用AS关键字来给查询的结果起个别名:
SELECT 2023-`Sage` AS `born_year` FROM student;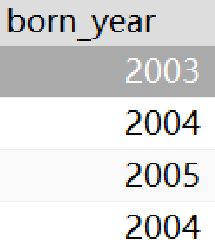
· 还可以给筛选出来的每一列都改名:
SELECT `Sname` AS `Name`,
2023-`Sage` AS `BirthYear`
FROM student;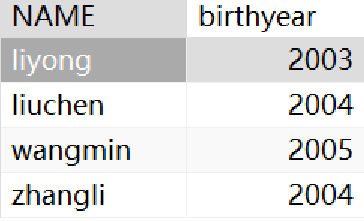
条件筛选
· 接下来我们要使用WHERE关键字来做条件筛选了。
· 下面列举了能跟在WHERE后面的谓词:

· 我们继续用这张学生表来做例子:
· 下面的代码可以筛选出表内所有CS系的学生的名字:
SELECT `Sname` FROM student WHERE `Sdept`=`CS`;· 下面的代码可以筛选出表内所有年龄大于18岁的学生的名字:
SELECT `Sname` FROM student WHERE `Sage`>18;· 下面的代码可以筛选出表内所有不是CS系的学生的名字:
SELECT `Sname` FROM student WHERE `Sdept`!=`CS`;
SELECT `Sname` FROM student WHERE `Sdept`<>`CS`; // <>也是不等于哦~· BETWEEN....AND....的使用:找到年龄在18到20岁之间的学生的姓名:
SELECT `Sname` FROM student WHERE `Sage` BETWEEN 18 AND 20;· NOT的使用:找到年龄不在18到20岁之间的学生的姓名:
SELECT `Sname` FROM student WHERE `Sage` NOT BETWEEN 18 AND 20;· IN的使用:找到CS系和IS系的学生姓名:
SELECT `Sname` FROM student WHERE `Sdept` IN (`CS`, `IS`);· 找到既不是18岁也不是20岁的学生的姓名:
SELECT `Sname` FROM student WHERE `Sage` NOT IN (18, 20);· 接下来介绍比较重要的字符匹配,它是一种模糊查询,需要使用LIKE关键字:
· 首先介绍百分号(%),它代表任意长度的字符串,如a%b就是要匹配以a开头,b结尾的任意字符串。
· 然后是下划线(_),它代表任意的单个字符,如a_就是要匹配以a开头,长度为2的字符串,如ab,ac。
· 然后是转义符(\),它用于加在特殊符号前,如百分号和下划线,这样SQL就会把它当普通字符看待,如\%就是字符%,\_就是字符_。
· 接下来举一些例子。
· 查询所有姓张的同学的学号:
SELECT `Sno` FROM student WHERE `Sname` LIKE "张%";· 查询不姓张的同学的学号:
SELECT `Sno` FROM student WHERE `Sname` NOT LIKE "张%";· 查询所有”张某某“的同学的学号:
SELECT `Sno` FROM student WHERE `Sname` LIKE "张__";· 查询第二个字是”阳“的同学的学号:
SELECT `Sno` FROM student WHERE `Sname` LIKE "_阳%";· 查询名字带下划线的同学的学号:
SELECT `Sno` FROM student WHERE `Sname` LIKE "%\_%";· 涉及空值的情况:假设有一个SC表,某些学生选修课程后没参加考试,所以有选课记录但没有成绩,查询缺少成绩的学生的学号以及相应的课程号:
SELECT `Sno`, `Cno` FROM `SC` WHERE `Grade` IS NULL;多条件运算
· 还是以这个学生表为例:
· 选出CS系的男生:
SELECT * FROM student WHERE `Ssex`="Male" AND `Sdept`="CS";· 选出所有男学生,不要CS系的:
SELECT * FROM student WHERE `Ssex`="Male" AND `Sdept`!="CS";· 选出”CS系的女学生”以外的学生:
SELECT * FROM student WHERE !(`Ssex`="Female" AND `Sdept`="CS");· 接下来用这张表来做点练习:
· 选出不大于19岁的男学生:
SELECT * FROM student WHERE `Ssex`="Male" AND `Sage`<=19;· 选出CS系以外的男学生:
SELECT * FROM student WHERE `Ssex`="Male" AND `Sdept`!="CS";· 查询不姓张的女学生的学号,姓名和院系:
SELECT `Sno`, `Sname`, `Sdept` FROM student WHERE `Sname` NOT LIKT "张%" AND `Ssex`="Female";· 选出CS系、IS系里名字带下划线的学生:
SELECT * FROM student WHERE `Sname` LIKE "%\_%" AND `Sdept` IN ("CS", "IS");· 一个小测试题:查询下列customer表中没有被id=2的客户推荐的客户的姓名。
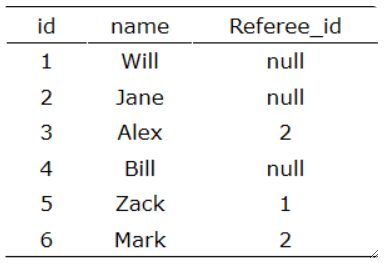
--注意是null的情况!!!
SELECT `name` FROM customer WHERE `Rederee_id`!=1 AND `Referee_id` IS NULL;· 多条件运算:注意AND的优先级比OR高!如筛选出下列表中所有工资少于1500元或大于2000元并且是03系的教师姓名:
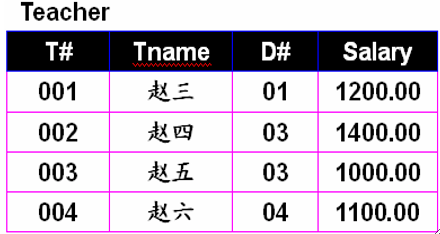
--注意OR语句要加上括号,否则会先运算后面的AND!!
SELECT `Tname` FROM Teacher WHERE (`Salary` < 1500 OR `Salary` > 2000) AND `D#`="03";排序语句
· 我们使用ORDER BY子句来对筛选出来的结果进行排序,它可以按一个或多个属性列进行排序。
· 如果要升序则使用ASC,降序则使用DESC。默认是升序。
· 比如查询全体学生,按年龄升序排序:
SELECT * FROM students ORDER BY `Sage` ASC;· 查询全体女同学,院系按首字母升序,同院系按年龄降序:
SELECT * FROM students
WHERE `Ssex`="Female"
ORDER BY `Sdept`, `Sage` DESC;· 限制结果个数:使用LIMIT关键字可以限制最后结果的数量,常与ORDER BY连用:
SELECT * FROM students
ORDER BY `Sage`
LIMIT 3; --限制最多3条结果统计函数
· 使用统计函数可以帮助我们对数值进行统计,常用的统计函数如下:

· 我们用下面这张Student表来演示一下统计函数:
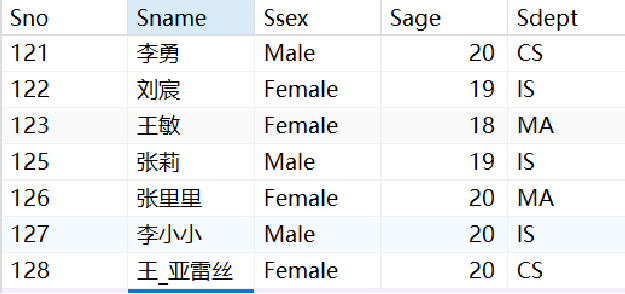
· 计算学生总人数:
SELECT COUNT(*) FROM `Student`;· 计算这些学生来自多少个学院:
SELECT COUNT(DISTINCT `Sdept`) FROM `Student`;· 找出姓张的同学的数量:
SELECT COUNT(*) FROM `Student` WHERE `Sname` LIKE "张%";
SELECT COUNT(`Sname` LIKE "张%") FROM `Student`;· 值得注意的是,聚集函数不能直接嵌套使用,如下面的句子是错误的:
SELECT MAX(COUNT(*)) FROM ...分组语句
· 我们会使用GROUP BY字句对筛选后的结果进行分组,它可细化聚集函数的作用对象。
· 如果未对查询结果分组,聚集函数就会作用于整个查询结果;分组之后,聚集函数就会分别作用于每个组。
· 该语句会按指定的一列或多列值分组,值相等的为一组。
· 接下来我们以这个学生表来做例子:
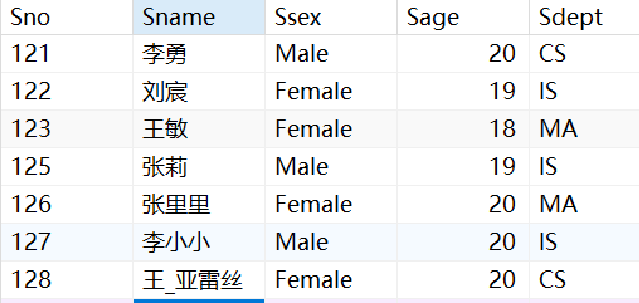
· 求每个系的平均年龄:
SELECT `Sdept`, AVG(`Sage`)
FROM student
GROUP BY `Sdept`;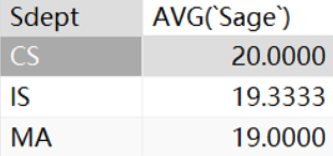
· 求每个系男生女生的平均年龄:
SELECT `Ssex`, `Sdept`, AVG(`Sage`)
FROM student
GROUP BY `Ssex`, `Sdept`;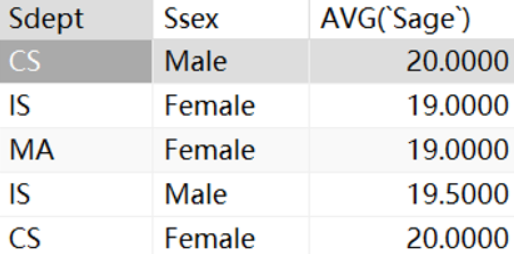
· 如果要对分组之后的结果再进行筛选,我们就不使用WHERE子句了,而是HAVING子句。
· 找出平均年龄小于20岁的系:
SELECT `Sdept`, AVG(`Sage`)
FROM student
GROUP BY `Sdept`
HAVING AVG(`Sage`) < 20;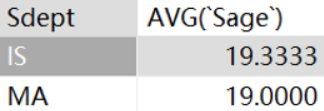
· 找出平均年龄小于20岁的系的人数:
SELECT `Sdept`, COUNT(*)
FROM student
GROUP BY `Sdept`
HAVING AVG(`Sage`) < 20;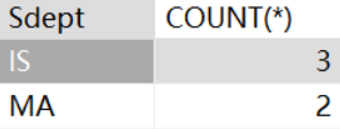
· 可以发现,HAVING子句是作用于组的,并从中选出满足条件的组,因此HAVING子句一定要跟在GROUP BY后面;而WHERE子句是作用于基表或视图的,并从中选出满足条件的元祖。
· 当然,HAVING是可以和WHERE连用的,用下面这个SC表举例:
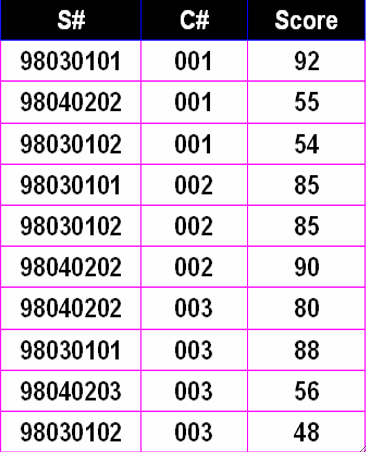
· 找出不及格课程大于等于2门的同学(60分或以上及格):
SELECT `S#`
FROM SC
WHERE `Score` < 60
GROUP BY `S#`
HAVING COUNT(*) >= 2;· 找出不及格人数大于等于10人的课程号:
SELECT `C#`
FROM SC
WHERE `Score` < 60
GROUP BY `C#`
HAVING COUNT(*) >= 10;· 接下来用这张Student表做习题:
· 查询姓张的学生的系的数量
SELECT COUNT(DISTINCT `Sdept`)
FROM Student
WHERE `Sname` LIKE "张%";
-- 注意以下写法是错误的,不可以用GROUP BY来代替DISTINCT,下面运行的结果是两行1,因为分出了2个组
/*
SELECT COUNT(*)
FROM student
WHERE `Sname` LIKE "张%"
GROUP BY `Sdept`;
*/· 查询每个系年龄最小的女生多少岁?请按Sdept - MAXage的格式输出:
SELECT `Sdept`, MIN(`Sage`)
FROM student
GROUP BY `Sdept`, `Ssex`
HAVING `Ssex` = "Female";· 找出女生人数大于等于2个的系:
SELECT `Sdept`
FROM student
GROUP BY `Sdept`, `Ssex`
HAVING COUNT(*) >= 2 AND `Ssex`="Female";