
数据库的设计流程
· 我们的数据库设计出来是为了解决实际问题的,因此要和实际业务挂钩。
· 当我们拿到一个需求的时候,要对它进行分析,设计概念模式。
· 然后把概念模式转换为逻辑模式,逻辑模式转换为物理设计,最后实现数据库。

· 接下来我们一步步看这个流程。
① 需求分析
该阶段需要明确应用的流程和需要用到的信息,明确用户的信息要求、处理要求和安全性、完整性要求。
举个例子:学生选课系统都需要些什么样的需求?学生要选课退课;老师查看自己要上的课;教务可以查看、修改所有记录等等。
② 概念设计和逻辑设计
概念和逻辑设计都是在设计数据库的概念模式,即选用一种数据模型(关系/层次/网络模型)
和数据模式(如关系模型则是表头)来描述现实世界。
在概念设计的时候给出一个E-R图,阐明数据库中包含什么实体(Entity,即表名),
以及它们之间的关系。
在逻辑设计的时候给出一个数据模式(Data Schema),用DDL在DBMS中定义,需要
依赖E-R图来定义数据库、表、内容、关系。
③ 物理设计
该阶段需要给出一个物理模式(Physical Schema),描述数据模式是如何存储在存储媒介上的,
如数据类型,主键、外键设计,索引设计等。
概念设计:E-R图
· E-R图全称为实体-关系数据模型(Entity-Relationship Data Model)。
· 概念的三要素:实体(想保存数据的一些东西),关系(实体与实体之间),属性(实体的特征)。
实体
· 实体描述了一组具有普遍性的实际个体的组合,这组个体拥有相同的特性,相同的关系和相同的语义。
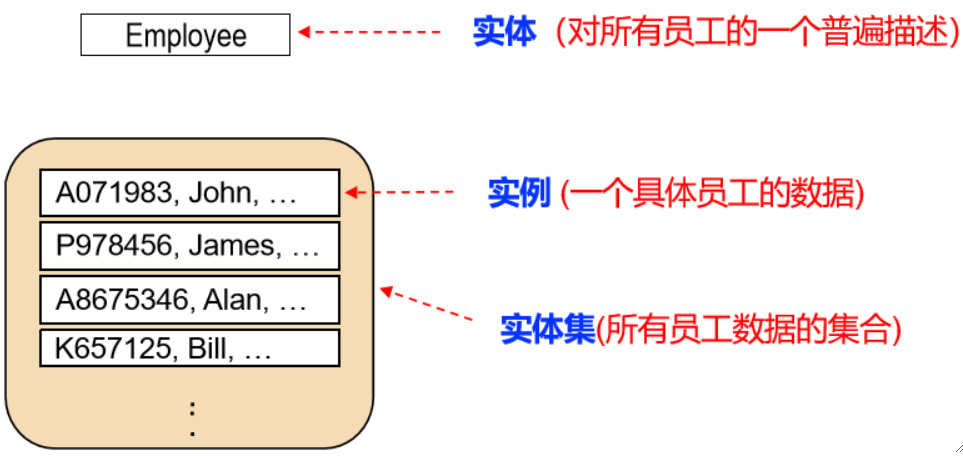
· 相同的特性指的是,都有名字、工号等;相同的关系指的是,例如,都“属于”某个部门,这个“属于”关系是共享的;相同的语义指的是,都用“员工”来定义这些实例。
属性
· 属性是实体的某种特性,并描述了这种特性对应的实例数据。
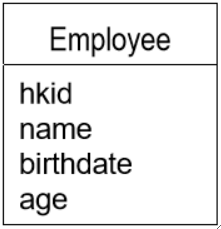
· 如上图,Employee实体就拥有四个属性。
· 值得注意的是,实体中的属性名字不能与实体名字相同!
· 大部分都属性值都是被物理存储的,但某些属性值也能通过计算得到(虚拟列)。
· 属性值可以为空值。
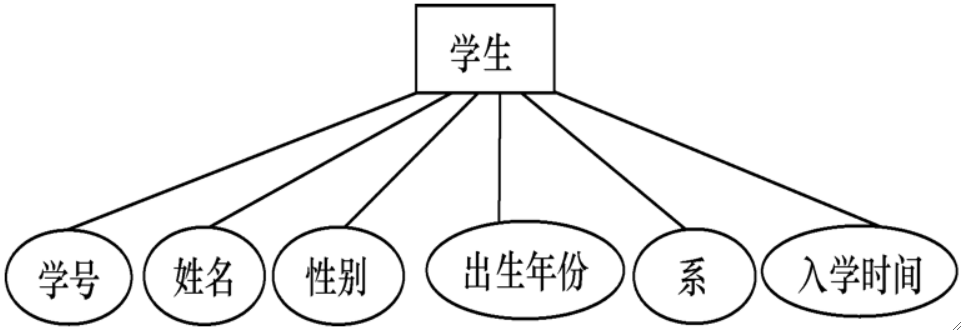
· 在E-R图中,属性一般用椭圆来表示,举个例子:
关系
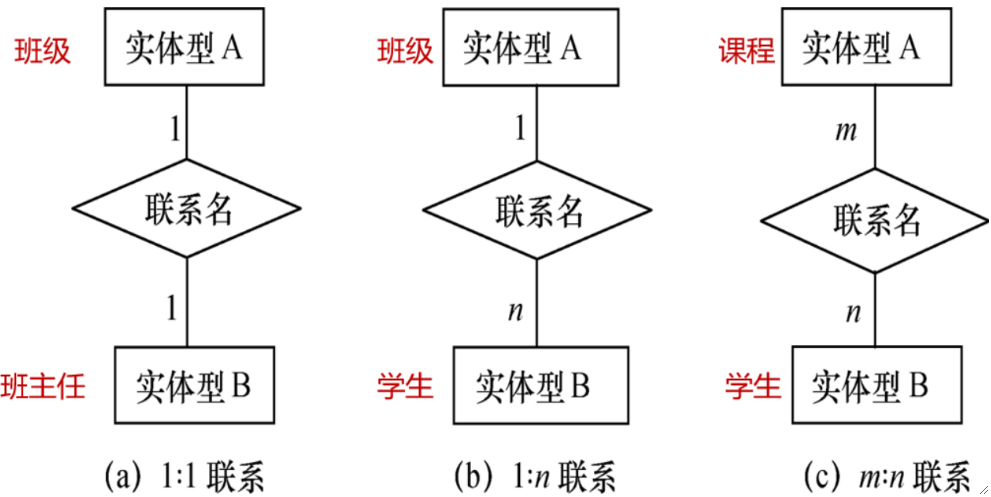
· 1V1的关系,实体之间可以有一对一、一对多、多对多的关系:
一个班级只能有一个班主任;一个班级有n个学生;每个学生有多个课程。
· 三角关系
· 单独关系
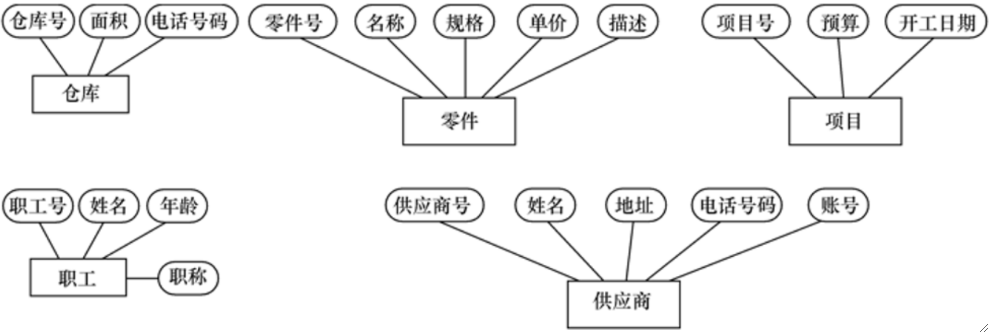
· 接下来我们来看一个实际例子,某个工厂物资管理的概念模型,设计的实体有:

· 首先我们把实体及其属性图画出来:
· 然后再把各个实体的联系画出来
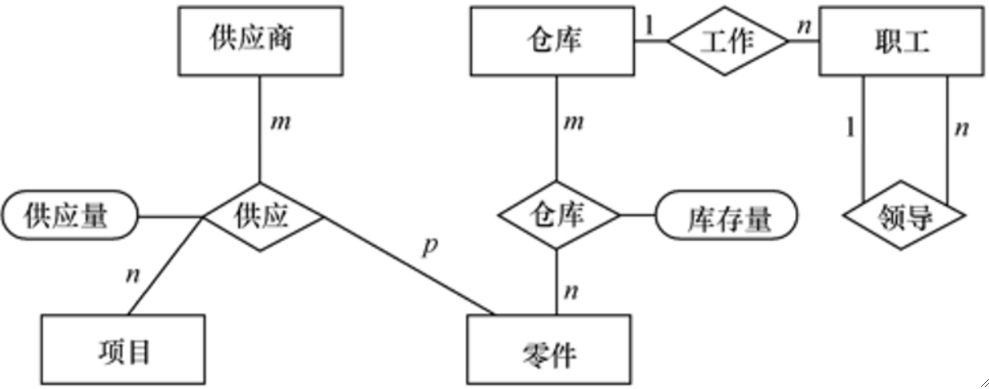
· 最后把属性补上去,就是完整的E-R图:
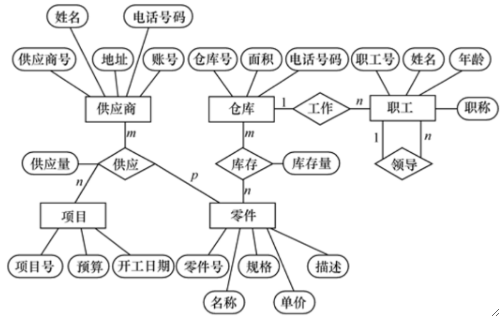
· 那这个设计的过程是否有一些技巧可取呢?当然是有的。
· 首先,我们需要考虑实体与属性划分的原则,怎么样算实体,怎么样算属性?
为了尽量简化E-R图,能作为属性对待的尽量作为属性对待。
作为属性,不能再具有需要描述的性质。属性必须是不可分的数据项,不能包含其他属性。
属性不能与其他实体具有联系,只能属于自身所在的实体。
E-R图的合并
· 各个局部应用所面向的问题不同,各个子系统的E-R图之间会存在许多不一致的地方,称之为冲突。
· 通过合并可以解决冲突。
· 子系统的E-R图之间的冲突主要有三类:
属性冲突,同名不同域,同属性不同单位。
命名冲突,同名异义,异名同义。
结构冲突,同一个对象抽象不同,同一个实体属性不同,实体联系不同。
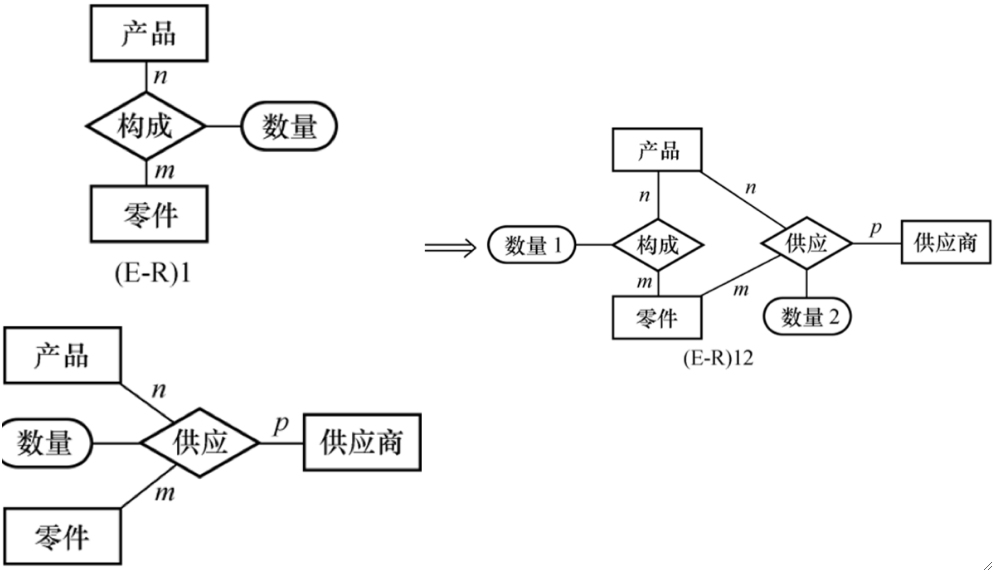
E-R图的冗余删除
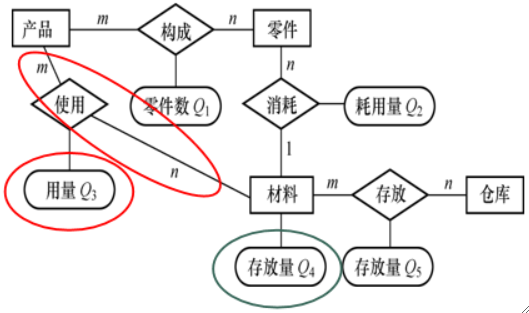
· 冗余的数据指的是可由基本数据导出的数据,冗余的联系是指可由其他联系导出的联系。
· 如下图中,Q2个材料构成了零件,Q1个零件构成了产品,因此做产品用了Q1*Q2个材料,但是存储了Q3,就是荣誉。
· 但也不是全部冗余都必须消除,如下面的Q4=sum(Q5),但为了方便还是保留,但每次修改Q5都要修改Q4。
逻辑设计:概念转向模型
· 接下来我们要学习,如何把E-R图变成数据库,在MySQL里就是关系数据库。
· 我们知道,E-R图由实体型、实体的属性、实体型之间的联系三个要素组成。
· 而关系模型的逻辑结构是一组关系模式的集合。
· 因此,将E-R图转换为关系模型,其实就是将实体型、实体的属性、实体型之间的联系转化为关系模式。
· 转换的原则如下
一个实体对应一个关系模式,在关系型数据库中就是一张表。
关系的属性=实体的属性,关系的码=实体的码。
实体之间不同的联系转换方式有所区别。
实体-关系模式之间的转换
· 正如上面所说的,一个实体就是一张表,实体的属性就是关系的属性,因此:
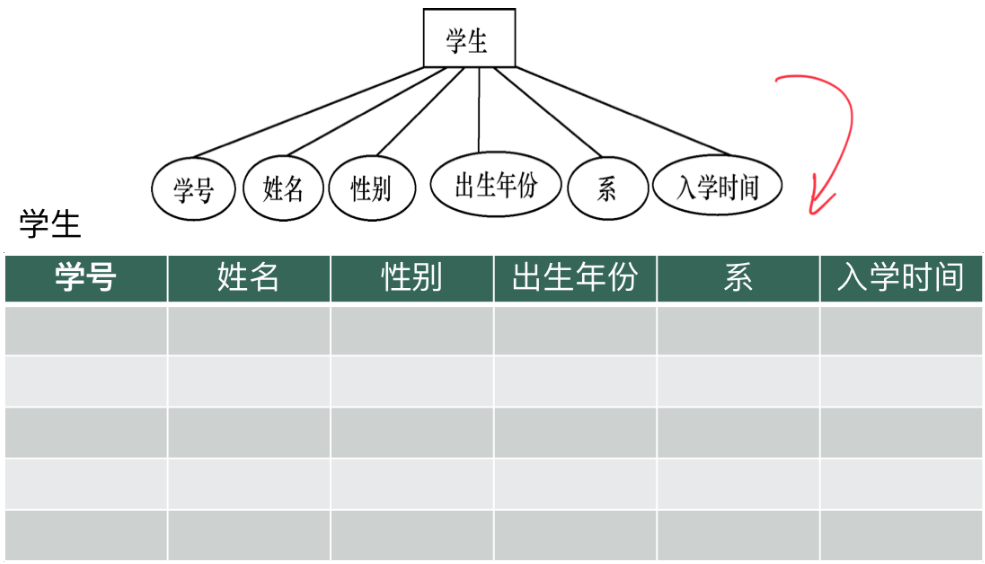
· 然后我们转换实体间的关系。
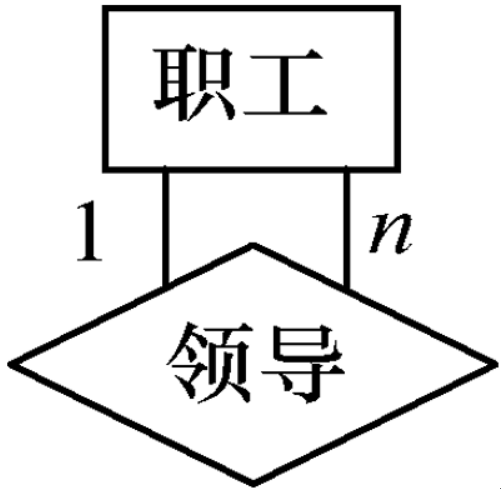
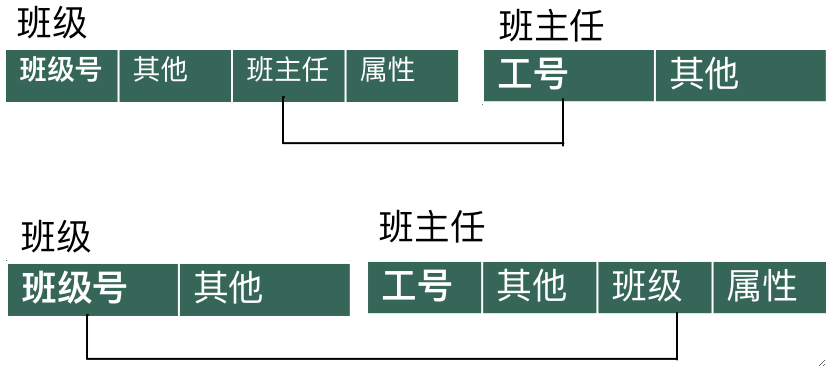
· 假设有一个1V1的关系为班级-班主任。

可以建一个独立的关系模式,即新建一张表来存储这两个实体的关系。

或者,我们可以直接合并两个关系,即在任意一张表添加一个属性,然后用外键连起来。
· 假设有一个1VN的关系为班级-学生。

同样可以建立一个独立的关系模式,即新建一张表来存储。

同样可以直接合并关系,但是注意,只能在N端加入1端的码。

· 假设有一个MVN的关系为课程-学生。

在这种关系里,只能通过新建一张表才能表达这两个实体之间的关系。

· 假设有一个多实体的关系,如课程-教师-学生。
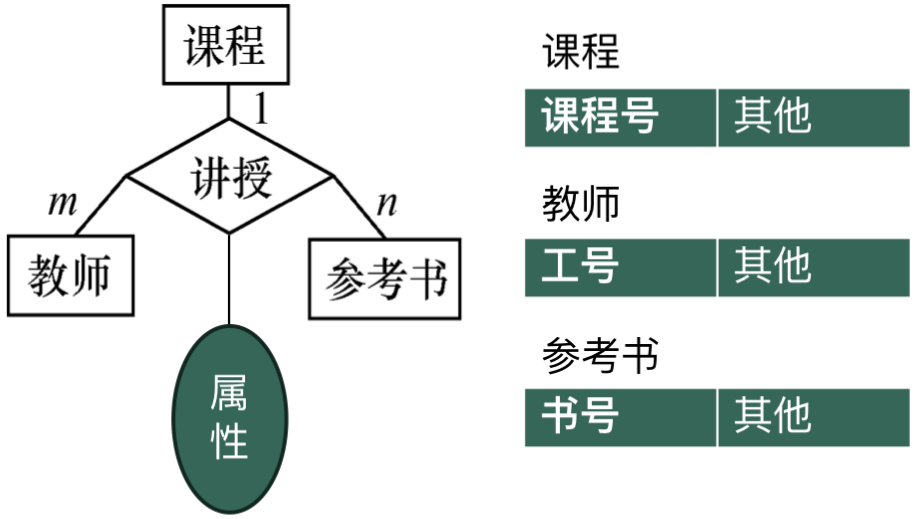
那也是只能通过新建一张表来把这三个实体联系起来。

关系模式的合并
· 关系模式的合并其实就是表的合并。目的是为了减少关系(表)的个数。
· 合并的方法也是非常简单,即将其中一个表的全部属性加入到另一个表中,然后去掉其中的同义属性(可能同名也可能不同),最后适当调整一下合并后新表属性的次序。
· 举个例子,下面有一张教师表和一张参考书表,它们都有一个属性是课程号,这样就存在冗余,因此我们可以合并两张表:

规范化与范式
· 关系第一范式(1NF,Normal Form),属性不可再分!即表中不能有小表。
· 除了第一范式,当然还有很多其它范式啦。我们给个定义,某一关系模式R为第n范式,可简记为R∈nNF。
· 一个低一级范式的关系模式,可以通过模式分解(Schema Decomposition)转换为若干个高一级范式的关系模式的集合,这个过程称为规范化(Normalization)。
· 在详细讲解规范化之前,我们需要先学习一些前置知识。
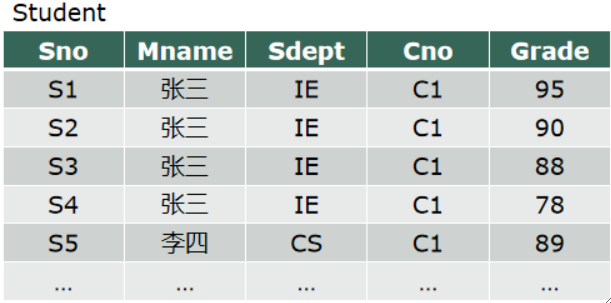
· 首先,我们看下面这张表,它是满足1NF的,但是有可能出现一些问题。
数据冗余:大量的数据反复出现。
更新异常:如果更换系主任(Mname),那很多条数据都需要被更新。
插入异常:如果一个系(Sdept)还没有学生,那主键Sno就没办法插入。
删除异常:如果某个系的学生全都毕业了,难道要把所有数据都删掉?系主任还在的呀!
· 出现这些问题,我们就说这张表的函数依赖设计的很差。
函数依赖(Functional Dependency)
· 定义:设R(U)是一个属性集U上的关系模式,X和Y是U的子集,若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等而在Y上的属性值不等,则称“X函数确定Y”或“Y函数依赖于X”,记作X→Y。
· 定义很抽象,我们来看例子。
· 描述一个学生关系,可以有学号、姓名、院系等属性。一个学号只对应一个学生,一个学生只在一个系中学习。“学号”值确定后,学生的姓名及所在系第值就被唯一确定。
· 那么我们就可以写Sname=f(Sno),Sdept=f(Sno),即Sno函数决定Sname,Sno函数决定Sdept。可记作Sno→Sname,Sno→Sdept。
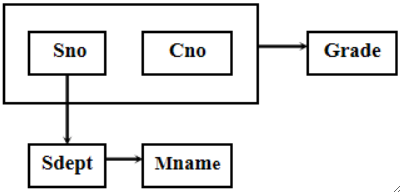
· 再详细一点,这个学生关系的关系模式属性集合为U={Sno,Sdept,Mname,Cno,Grade}。
· 根据现实世界已知的事实,我们知道:
一个系有若干学生,但一个学生只属于一个系,因此Sno→Sdept。
一个系只有一名系主任,因此Sdept→Mname。
一个学生可以选修多门课程,每门课程有若干学生选修,因此没有确定关系。
每个学生学习一门课程都有一个成绩,因此(Sno,Cno)→Grade。
· 画出图来就可以有:
· 对于某些特殊情况的函数依赖,我们有专门的定义:
平凡函数依赖:X→Y,Y\subsetneqX(天然成立)。
非平凡函数依赖:X→Y,Y\not\subsetneqX(有额外语义,如学号→姓名)
完全函数依赖:若X→Y,且对于任意X的一个真子集X'都有X'\not\toY,则称Y对X完全函数依赖,记为X\xrightarrow{F}Y。
部分函数依赖:若X→Y,但存在真子集X'使得X'→Y,则称Y对X部分函数依赖,记为X\xrightarrow{P}Y。
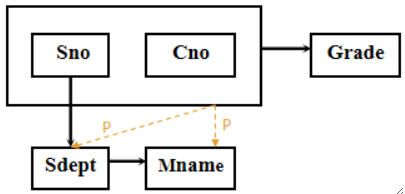
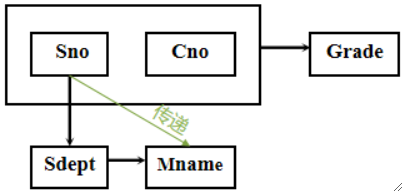
传递函数依赖:若X→Y,Y→Z,Y\not\subsetneqX,Z\not\subsetneqY,则称Z对X传递函数依赖。
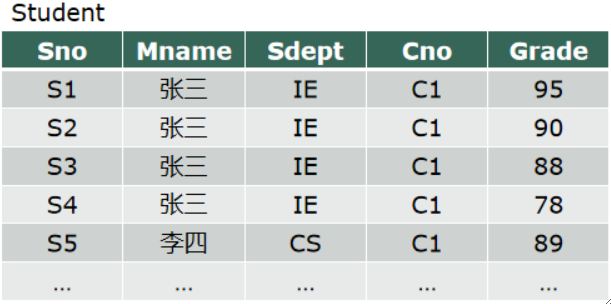
· 明白了函数依赖之后,我们还要复习“码”的概念,现在我们可以用函数依赖的概念来解释各种码了。
· 候选码,我们知道,是可以唯一地标识一个元组的最小属性组,是主码的候选。用函数依赖来解释,就是所有属性完全函数依赖的属性组。假设K为关系R(U)中的一个属性组,若K![]() U,则K为候选码。
U,则K为候选码。
· 主码,就是从候选码中挑一个。主属性,就是任何一个候选码中的属性。非主属性,顾名思义了。全码,即整个属性组才能唯一标识一个元组。
· 举个例子,在下面这张表中,候选码就是(Sno,Cno),主码也是,主属性就是Sno,Cno,非主属性就是Sdept,Mname,Grade。
第二范式(2NF)
· 定义:一个关系满足第一范式,且每个非主属性完全依赖于任意一个候选码。
· 我们上面这张Student表很明显不满足第二范式,因为Mname和Sdept是部分依赖于主码的。
· 修正方式很简单,拆成符合第二范式的多个关系(即分成两张表)即可:
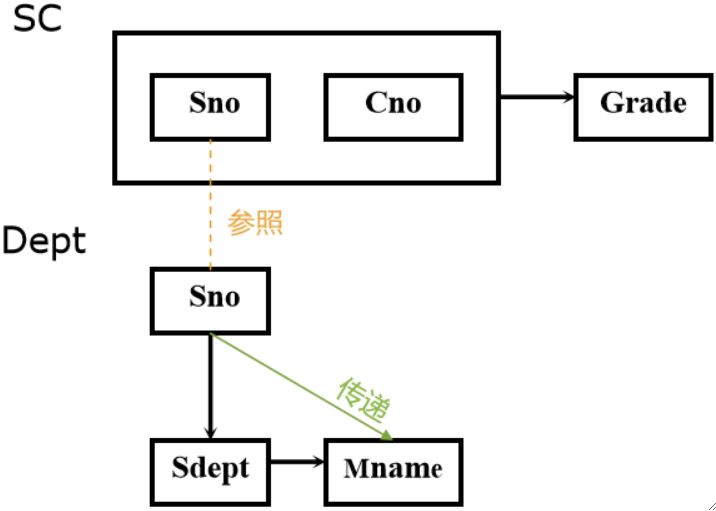
· 可以看到,第二范式其实是在消除非主属性对码的部分函数依赖!
· 这下SC正常了,之前提到的数据冗余、更新异常等问题就被消解掉了,可不幸的是,这些问题转移到Dept表上了(笑死)。
· 这咋办?用第三范式修正!
第三范式(3NF)
· 定义:一个关系满足第一范式,且每一个非主属性既不传递依赖于候选码,也不部分依赖于候选码。
· 可以发现,定义后面的“也不部分依赖于候选码”其实是第二范式的内容,因此,一个关系满足3NF也会满足2NF。
· 根据定义,我们把Dept表再拆分:
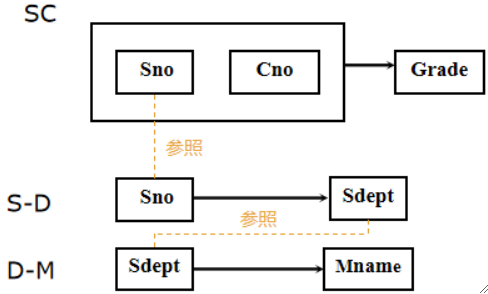
· 可以发现,第三范式是在消除非主属性对码的传递函数依赖!
· 我们再来看一个例子,一个仓库管理关系,每个管理员只管理一个仓库,每种货品可以存放在多个仓库,那么就有函数依赖如下:
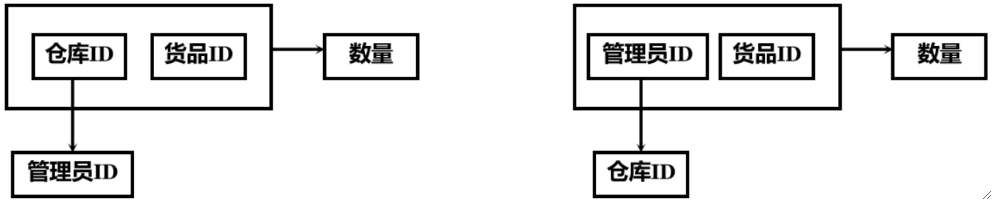
· 它看上去也满足3NF,但是有点奇怪,因为主属性对其他候选码存在部分函数依赖,就像(仓库ID,货品ID)部分函数依赖于管理员ID。
· 为了消除这个问题,两位科学家(Boyee,Codd)提出来修正的第三范式(BCNF)。
· 定义:设关系模式R<U,F>满足1NF,若X→Y且Y\not\subsetneqX时(非平凡函数依赖)X必含有候选码,则该关系模式满足BCNF。
· 说点人话,就是在一个关系模式R中,若每一个决定属性集都包含候选码,则R满足BCNF。决定属性,即若X→Y,则X就是决定属性。
· 有了BCNF,可以发现,所有主属性都完全函数依赖于每个不包含它的候选码,这消除了主属性对码的部分和传递函数依赖。
· 如果一个关系数据库中的所有关系模式都属于BCNF,那么在函数依赖的范畴内,它已经实现了模式的彻底分解,达到了最高的规范化程度,消除了插入和删除异常。
第四范式(4NF)
· 首先,第四范式是用来解决多值依赖的,不是用来解决函数依赖的,那么什么是多值依赖呢?
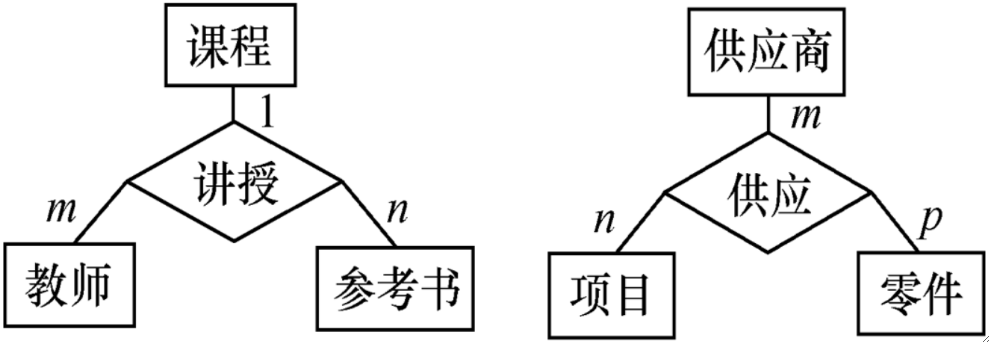
· 假设有一个关系模式如下,一门课程可由多个教师讲授,每个老师可以使用多本参考书。
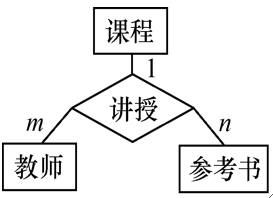

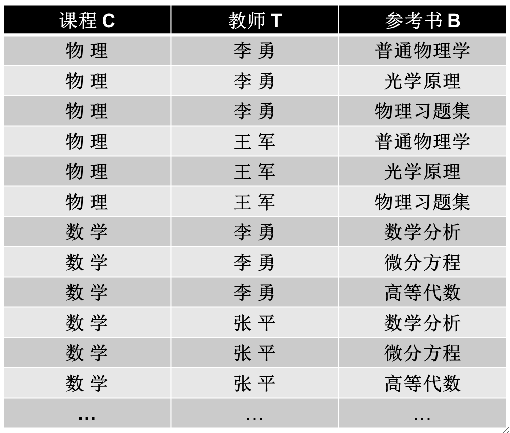
· 可以看到,课程可以确定教师,也可以确定参考书,但是教师和参考书之间互不影响,这就是多值依赖。
· 定义:设R(U)是属性集U上的一个关系模式。X,Y,Z是U的子集,并且Z=U-X-Y。关系模式R(U)中多值依赖X→→Y成立,并且仅当对R(U)的任一关系r,给定的一堆(x,z)值,有一组Y的值,这组值仅仅决定于x值而与z值无关。
· 以上面的例子,一门课有一组老师负责,和参考书无关,则C→→T。同理C→→B。
· 既然多值依赖的定义是这样的,那就意味着,我们需要使用全码,即所有属性的组合,才能唯一确定一条元组。
· 全码带来的缺点有很多:
数据冗余度大,有多少教师、参考书就要存多少次。
增加操作复杂:假设一门课增加一个老师,那根据这门课有多少参考书,就要插入多少次。
删除操作复杂:假设一门课去掉一本参考书,那根据这门课有多少老师,就要删除多少次。
修改操作复杂:假设一门课修改一本参考书,那根据这门课有多少老师,就要修改多少次。
· 既然多值依赖带来这么多确定,那要如何解决多值依赖呢?靠第四范式!
· 定义:限制关系模式属性之间不允许出现非平凡且非函数依赖的多值依赖。
· 在上面的例子中,我们把(课程,教师,教科书)拆成(课程,教师)和(课程,参考书)即可,虽然仍然有多值依赖C→→T,C→→B,但因为已经是两张表了,因此这是一个平凡的多值依赖,满足4NF。
总结
· 关系模式规范化步骤:
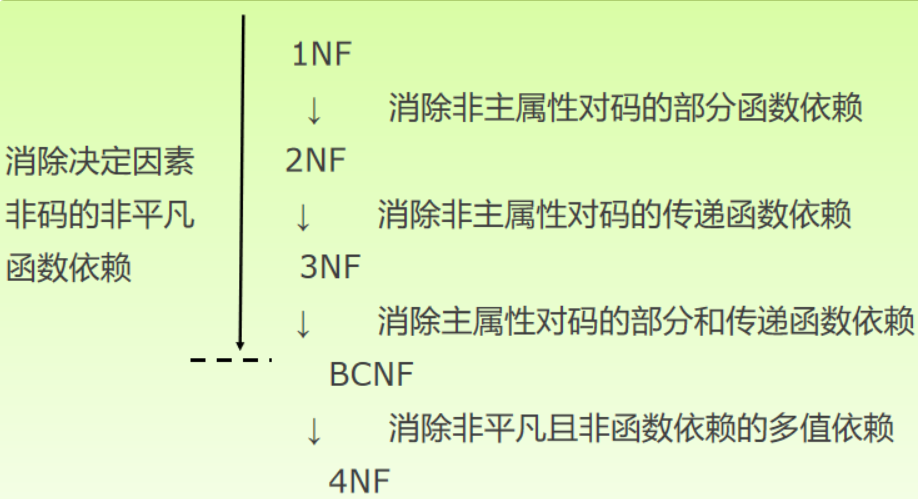
· 注意,不能说规范化程度越高的关系模式越好,必须对现实世界的实际情况和用户应用需求作进一步分析,确定一个合适的,能够反映现实世界的模式。