
前言
· 有很多人对Git是这样评价的:

· 如果自上而下地学习Git,即直接从Git的命令开始学,就会让人感到很奇怪。
· 尽管Git的命令接口设计的很抽象,但是其底层设计和思想是非常优雅的!
· 因此,自下而上地从Git的数据模型开始学习,再学习如何操作命令,会更舒服!
快照(Snapshot)
· 快照是Git存储历史记录使用的一个概念。
· 首先,在Git的术语中,文件(Files)会被称为Blob对象,文件夹(Folders)会被称为Tree对象。
· 例如,在下面的图片中,root文件夹包含了一个foo文件夹和一个baz.txt,foo文件夹内包含了一个bar.txt。

· 这其中,root、foo就被称为tree,bar.txt和baz.txt就被称为blob。
· 当你创建一个快照的时候,Git会像你给桌面上的物品拍照一样,只记录拍下的照片,而不是桌子上的所有物品,当你要把桌子恢复成照片上的样子的时候,直接对着照片摆放即可。
历史记录建模
· 现在,有了一个一个的快照(历史版本),要如何把这些快照组合到一起呢?
· 毫无疑问,线性历史记录是最简单的模型,只需要按时间顺序把所有快照组合在一起即可,不过Git并没有采用这个模型。
· 在Git中,历史记录是由一系列快照组成的有向无环图。听上去很高级,其实,只要记得每一个快照都会有一堆的“父辈(Parents)”即可。
· 具体解释如下。
① 首先,你的程序有一个初始版本,我们将它命名为ver 1.0,在8月10日推送给Git。

② 然后,在8月11日,你给这个程序加了新功能,再次推送给Git,那么就会变成这样。
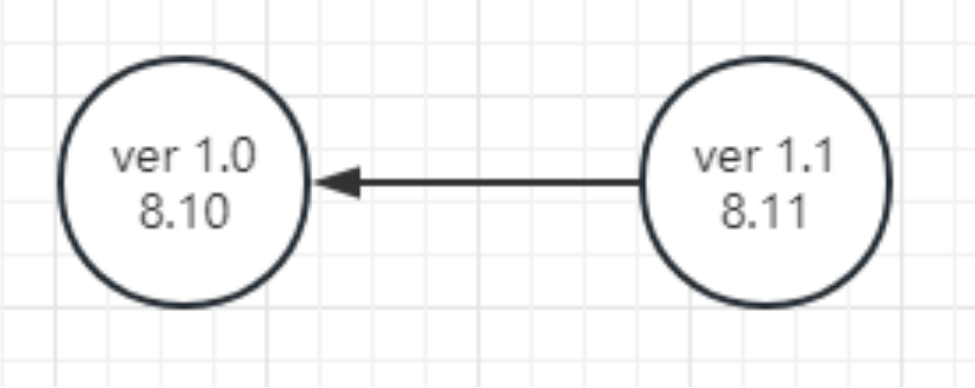
在这里,我们就说ver 1.1的父辈就是ver 1.0 。
③ 然后,在8月12日,你又加了新功能,又推送。
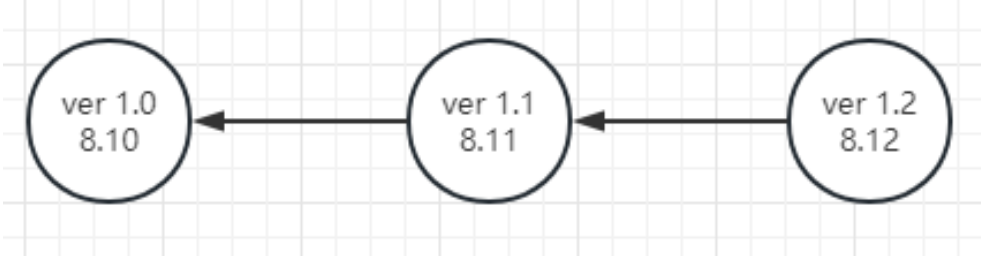
此时,ver 1.2的父辈就是ver 1.1和ver 1.0 。
④ 在8月13日这一天,你的程序出了bug,你需要修bug;除此之外,你还要继续增加新功能。你想让你的朋友帮你修bug,你去做新功能。那么,在这一天,就有2个推送到Git里。
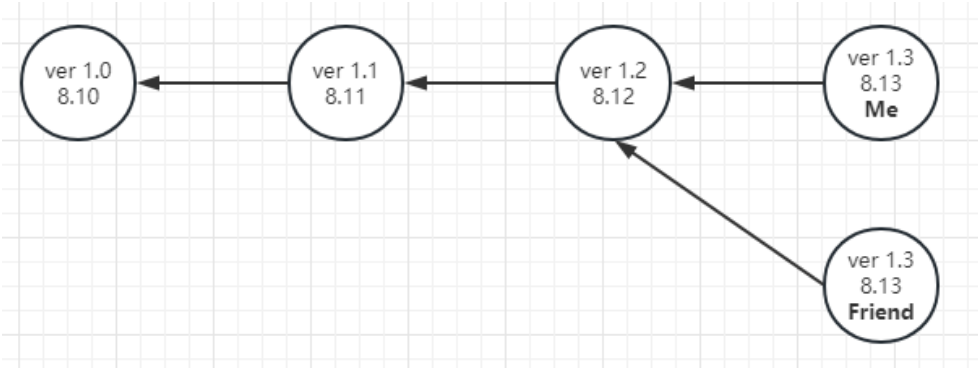
很明显,Me的ver 1.3和Friend的ver 1.3的父辈都是ver 1.2,也就是说,他们两个拥有同一个父辈。
⑤ 在8月14日这一天,你决定把你的ver 1.3和朋友的ver 1.3组合到一起,但不添加任何其他功能。
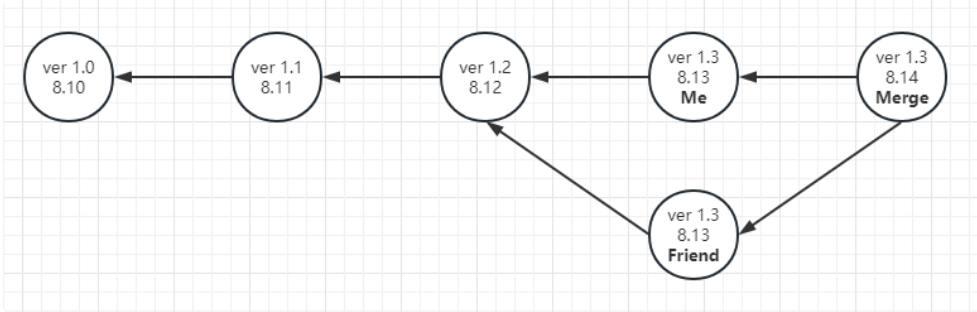
很明显,今天我们把昨天的两个快照合并(Merge)到了一起,形成一个新的快照,而这个快照的父辈有两个,Me和Friend。
· 以上就是Git的历史记录建模的简单介绍,当然,Git的内部实现会更复杂。
Git的数据结构
· 接下来将以伪代码的形式展现Git内的各种数据结构。
· 首先,我们刚刚说了,Git内有Blob和Tree。
typedef blob = array<byte>;
typedef tree = map<string, tree | blob>;很明显,blob是文件,所以本质上就是一个字节数组;tree是一个映射,由一个名字映射到另一个tree或一个blob上。
· 然后,在Git中,一个一个的快照会被称为提交(Commit),它也拥有自己的数据结构。
typedef commit = struct {
parent: array<commit>
author: string
message: string
snapshot: tree
}一个提交由很多数据组成,比如它的所有父辈(parent),该提交的作者(author),一些附加信息(message),以及这个提交真实存储的内容(snapshot)。
· 然后,Git又定义了一种叫做对象(Object)的东西,它可以是提交(Commit)、Blob或Tree。
typedef object = commit | blob | tree;有点像Java或C++中,Object是一个抽象父类,而commit、blob和tree是其子类。
· Git在存储数据时,所有的对象都会基于它们的 SHA-1哈希 寻址。
· PS:SHA-1是一种算法,你给他一个文件或别的什么东西,他会给你返回一串16进制、40个字符的字符串,用这个字符串可以唯一地标识你输入给它的东西。
objects = map<string, object>
def store(object):
id = sha1(object)
objects[id] = object
def load(id):
return objects[id]可以看到,在store函数中,先计算了传入的object的哈希值,然后再存储,在load函数中,会根据哈希值直接返回objects这个map中对应的对象。
· 因为有了唯一标识,所以像tree和commit这种需要保存其他tree和commit的对象,就不需要真正地去保存其他对象的文件了,而是保存一个哈希值即可。
· 现在所有的快照都可以用哈希值来唯一标识了,但这有个不好的地方,哈希值太难记了,而且这一串东西对于人类来说没有任何意义。
· 针对这个问题,Git的解决方法是引用(Reference),其实本质上就是一个映射,重命名。
references = map<string, string>
def update_reference(name, id):
references[name] = id
def read_reference(name):
return references[name]
def load_reference(name_or_id):
if name_or_id in references:
return load(references[name_or_id])
else:
return load(name_or_id)· 与对象不同的是,引用是可以修改的,比如一开始master指向一串4a2ef....的哈希值,在添加了一个新的快照之后,你可以让master重新指向最新快照5d2ad....。
· 这样,Git就可以实现用一个有意义的名称来表示每一个快照了。
Git仓库
· 有了上述的概念,就可以对Git仓库(Git Repository)下一个定义了:对象和引用。
· 在硬盘上,Git仅存储对象和引用,因为其数据结构就只包含这些东西,所以你才会觉得Git使用的空间非常的少。
· 所有的Git命令都是对应着提交树(图)的各种操作,当你输入git指令的时候,可以尝试思考一下底层的图数据结构是如何运作的。
暂存区
· 暂存区和Git的数据结构没有任何关系,但是它确实是在提交的过程中的一环。
· 考虑如下场景:你的软件有两个新功能,但是你希望每个功能单独提交一个新的快照,第一个提交包含功能1,第二个包含功能;或者你在调试程序的时候有很多log语句,但是在提交的时候你想只提交有实际作用的语句而不提交log语句。
· Git解决上述问题的办法就是暂存区(Staging Area)机制,它允许你选择下次提交中包含哪些内容。