· 记录今天刷到的一道算法题,评论区大佬的解法真的太浪漫了QAQ。
· 题目在LeetCode上,链接在是这里~
· 难度是简单,但是也学到了不少东西,评论区大佬的解法更是让人眼前一亮!特此记录!
· 我的解法其实很简单粗暴,因为两个链表相交,所以必然在交点以及后面的节点的地址都会相同。
· 因此,直接用一个unordered_set来记录A表中的所有节点,然后通过find方法去遍历B表,找到第一个相同的节点地址就是相交点。
· 代码如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
unordered_set<ListNode*> set;
ListNode* tmpA = headA;
ListNode* tmpB = headB;
while (tmpA != nullptr) {
set.insert(tmpA);
tmpA = tmpA->next;
}
while (tmpB != nullptr) {
if (set.find(tmpB) != set.end()) {
return tmpB;
}
tmpB = tmpB->next;
}
return NULL;
}
};
· 首先贴上大佬的解法链接,在这里~
· 其实核心思想,就是用两个指针,分别指向A表和B表,这两个指针首先走一遍自己的表,然后在尽头回到对方的表开始走。
· 这样做的好处是,两个指针走的“路程”是相当的,又因为它们每次只走一个节点,即速度相当,那么它们总会在某个节点相遇!
· 一句话,就是抹平了两个链表的长度不等,又因为我们构造了循环,所以他们肯定会相遇!
· 大佬画了图如下:
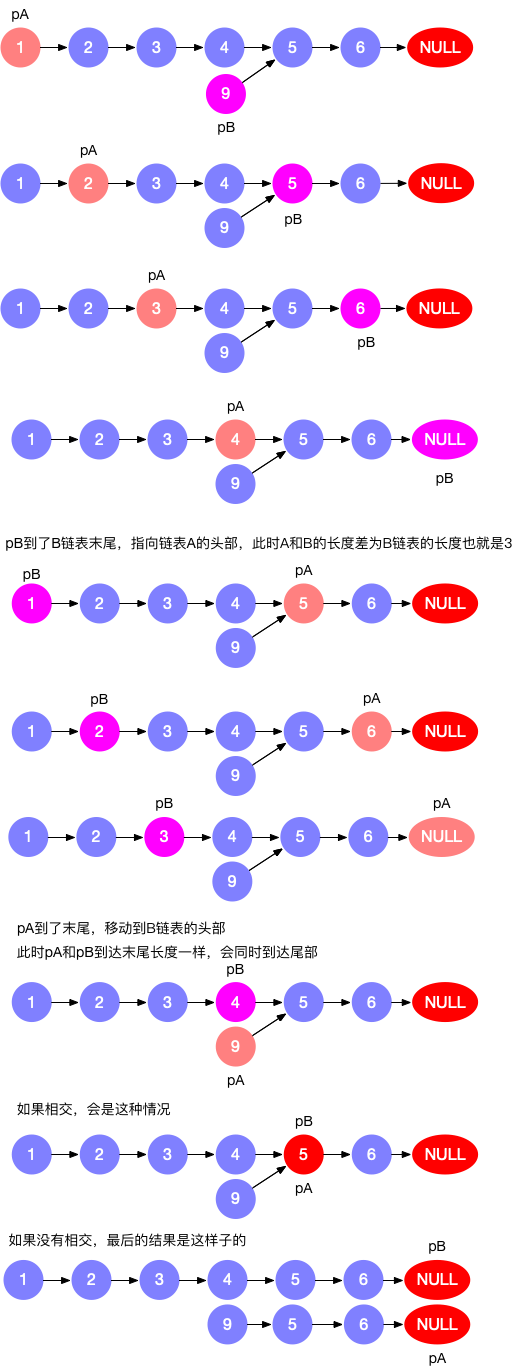
· 最后给上大佬的代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
// 两个指针不断走对方的路,直到遇到彼此
if (headA == nullptr || headB == nullptr)
return NULL;
ListNode* pA = headA;
ListNode* pB = headB;
while (pA != pB) {
pA = pA == nullptr ? headB : pA->next;
pB = pB == nullptr ? headA : pB->next;
}
return pA;
}
};
· 除了算法的精妙,最有意思的还是看评论区网友的评论。
· 本文的标题和摘要都是出自评论区,谁说刷算法的人都是理工男,明明很有温度好不好QAQ
